
工作的时候很多东西是用不到的,这不,等到再面试的时候,本应该掌握的东西有些又被大风吹走了😂,八股文还是得搞一搞。
JVM
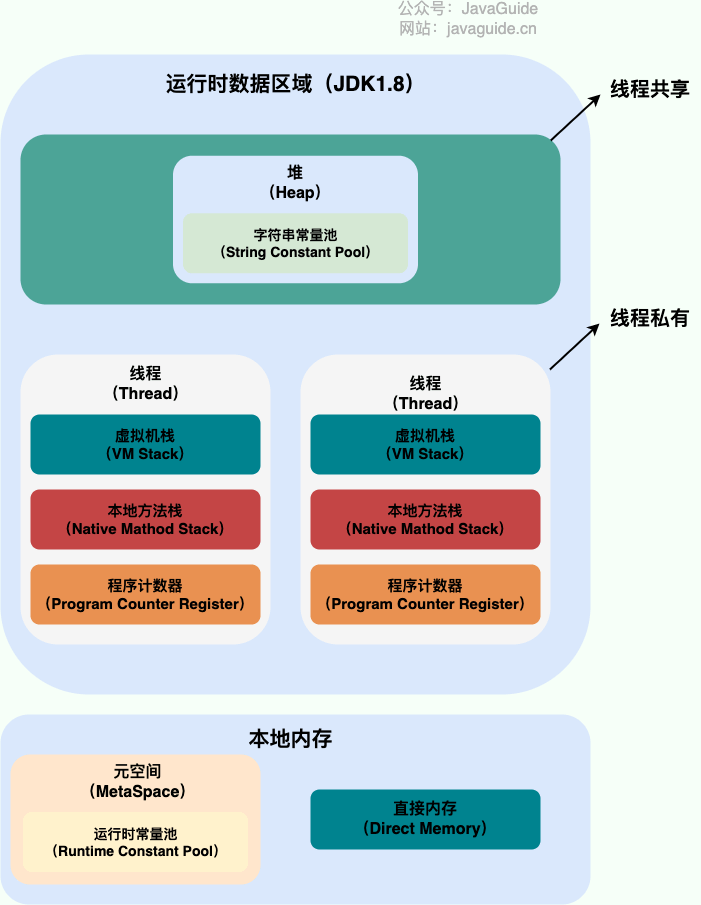
JVM内存模型
从 JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
线程私有
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡。栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址。
局部变量表 主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
操作数栈 主要作为方法调用的中转站使用,用于存放方法执行过程中产生的中间计算结果。另外,计算过程中产生的临时变量也会放在操作数栈中。
动态链接 主要服务一个方法需要调用其他方法的场景。在 Java 源文件被编译成字节码文件时,所有的变量和方法引用都作为符号引用(Symbilic Reference)保存在 Class 文件的常量池里。当一个方法要调用其他方法,需要将常量池中指向方法的符号引用转化为其在内存地址中的直接引用。动态链接的作用就是为了将符号引用转换为调用方法的直接引用。
本地方法栈和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
线程共享
堆是Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
多线程
volatile
volatile 关键字其实并非是 Java 语言特有的,在 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。如果我们将一个变量使用 volatile 修饰,这就指示 编译器,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
在 Java 中,volatile 关键字除了可以保证变量的可见性,还有一个重要的作用就是防止 JVM 的指令重排序。 如果我们将变量声明为 volatile ,在对这个变量进行读写操作的时候,会通过插入特定的 内存屏障 的方式来禁止指令重排序。
synchronized
synchronized关键字加到static静态方法和synchronized(class)代码块上都是是给 Class 类上锁;synchronized关键字加到实例方法上是给对象实例上锁;- 尽量不要使用
synchronized(String a)因为 JVM 中,字符串常量池具有缓存功能。
垃圾回收
标记-清除法:效率低,标记清除后会有大量的的碎片。
标记-复制法:空间利用率低。
标记-整理法:类似标记清除,但会整理也就没有碎片。
分代收集:新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
数据库
数据库优化
选取最适用的字段属性、使用连接(JOIN)来代替子查询(Sub-Queries)、使用联合(UNION)来代替手动创建的临时表、事务、锁定表、使用外键、使用索引、优化的查询语句
数据库设计的步骤
- 需求分析 : 分析用户的需求,包括数据、功能和性能需求。
- 概念结构设计 : 主要采用 E-R 模型进行设计,包括画 E-R 图。
- 逻辑结构设计 : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。
- 物理结构设计 : 主要是为所设计的数据库选择合适的存储结构和存取路径。
- 数据库实施 : 包括编程、测试和试运行
- 数据库的运行和维护 : 系统的运行与数据库的日常维护
数据库事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务都有 ACID 特性:只有保证了事务的持久性D、原子性A、隔离性I之后,一致性C才能得到保障。
事务的传播机制
多个事务的方法相互调用时Spring提供的7中不同的传播特性,保证事务的正常执行。
并发事务带来的问题
脏读,修改丢失,不可重复读,幻读。
数据库的隔离级别
- READ-UNCOMMITTED(读取未提交)
- READ-COMMITTED(读取已提交)
- REPEATABLE-READ(可重复读) – 默认隔离级别
- SERIALIZABLE(可串行化)
Redis 和 RabbitMQ
Redis 中的数据类型: String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)、HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)、Stream(5.0后,可以做消息队列,但消息丢失和堆积问题不好解决)
Redis 事务(没有rollback不建议使用)
MULTI 命令后可以输入多个命令,Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 EXEC 命令后,再执行所有的命令。
DISCARD 命令取消一个事务,它会清空事务队列中保存的所有命令
WATCH 命令监听指定的 Key,当调用 EXEC 命令执行事务时,如果一个被 WATCH 命令监视的 Key 被 其他客户端/Session 修改的话,整个事务都不会被执行。
常用的设计模式
软件设计原则:

- 工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。