
传输控制协议 TCP 概述
TCP 协议比较复杂,这里只对 TCP 协议进行一般介绍。
TCP 最主要的特点
- TCP 是面向连接的运输层协议。也就是说,应用程序在使用 TCP 协议之前,必须先建立 TCP 连接。在数据传输完毕后,必须释放已经建立的 TCP 连接。
- 每一条 TCP 连接只能有两个端点(endpoint)。每一条 TCP 连接只能是点对点(一对一)。
- TCP 提供可靠交付的服务。通过 TCP 连接传送的数据,无差错、不丢失、不重复并且按序到达。
- TPC 提供全双工通信。
- 面向字节流。TCP 中的 “流” 指的是流入到进程或从进程流出的字节序列。“面向字节流” 的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成一连串的无结构的字节流。TCP 并不知道所传达的字节流的含义。TCP 不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块具有大小对应的关系,但接收方应用程序收到的字节流必须和发送方应用程序发出的字节流完全一样。
TCP的连接
TCP 把连接作为最基本的抽象。每一条 TCP 连接有两个端点。这个端点叫做套接字(socket)或插口。根据 RFC 973 的定义:端口号拼接到(concatenated with)IP 地址即构成了套接字。每一条 TCP连接唯一的被通信两端的两个端点(即两个套接字)所确定。即:
TCP连接 ::= {socket1,socket2} == {(IP1:port1),(IP2:port2)}
总之,TCP 连接就是由协议软件所提供的一种抽象。有的时候我们为了方便说,在一个应用进程和另一个应用进程之间建立了一条 TCP 连接,但请记住:TCP 连接的端点是个很抽象的套接字,即(IP : 端口号)。也应记住:同一个 IP 地址可以有多个不同的 TCP 连接,而同一个端口号也可以出现在多个不同的 TCP 连接中。
可靠传输的工作原理
TCP 发送的报文段是交个 IP 层传送的。但 IP 层只能提供尽最大努力交付的服务,因此,TCP 必须采取适当的措施来使得两个运输层之间的通信编的可靠。
停止等待协议
在计算机网络发展的初期,通信链路不太可靠,因此在链路层传送数据时都要采用可靠的通信协议。其中最简单的协议就是 “停止等待协议”。
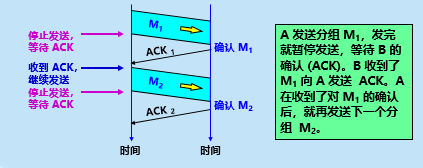
停止等待”就是每发送完一个分组就停止发送,等待对方的确认。在收到确认后再发送下一个分组。
无差错情况
出差错情况
问题 1
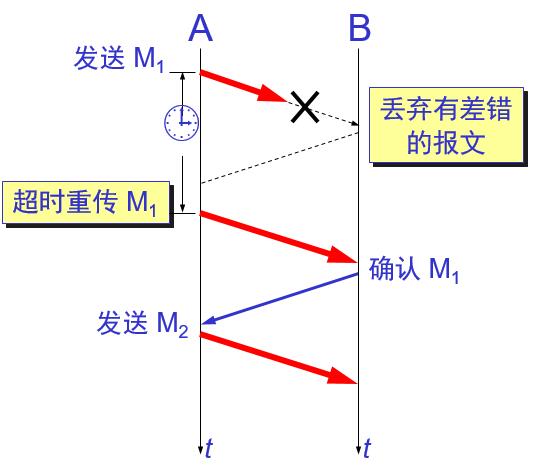
- 在接收方 B 会出现两种情况:
(1)B 接收 M1 时检测出了差错,就丢弃 M1,其他什么也不做(不通知 A 收到有差错的分组)。
(2)M1 在传输过程中丢失了,这时 B 当然什么都不知道,也什么都不做。
解决方法:
超时重传A 为每一个已发送的分组都设置了一个
超时计时器。A 只要在超时计时器到期之前收到了相应的确认,就撤销该超时计时器,继续发送下一个分组 M2 。若A在超时计时器规定时间内没有收到B的确认,就认为分组错误或丢失,就重发该分组。
问题 2
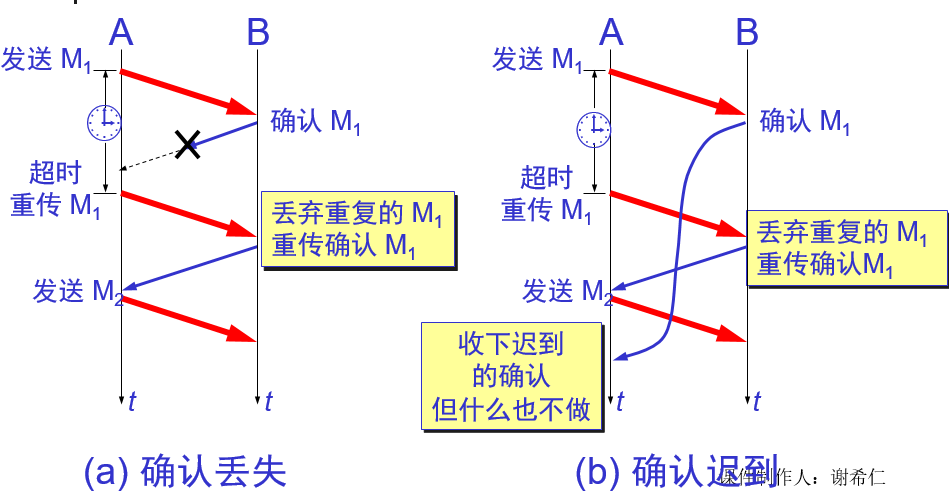
- 若分组正确到达B,但B回送的确认丢失或延迟了,A未收到B的确认,会超时重发。B 可能会收到重复的 M1 。B如何知道收到了重复的分组,需要丢弃呢?
解决方法:
编号
A为每一个发送的分组都进行编号。若B收到了编号相同的分组,则认为收到了重复分组,丢弃重复的分组,并回送确认。
B为发送的确认也进行编号,指示该确认是对哪一个分组的确认。
A根据确认及其编号,可以确定它是对哪一个分组的确认,避免重发发送。若为重复的确认,则将其丢弃。
像上述的这种可靠的传输协议常称为自动重传协议 ARQ(Automatic Repeat reQuest)。
停止等待协议的优点是简单,缺点是信道的利用率太低。为了提高传输效率,发送方可以不适用低效率的停止等待协议,而是采用流水线传输。
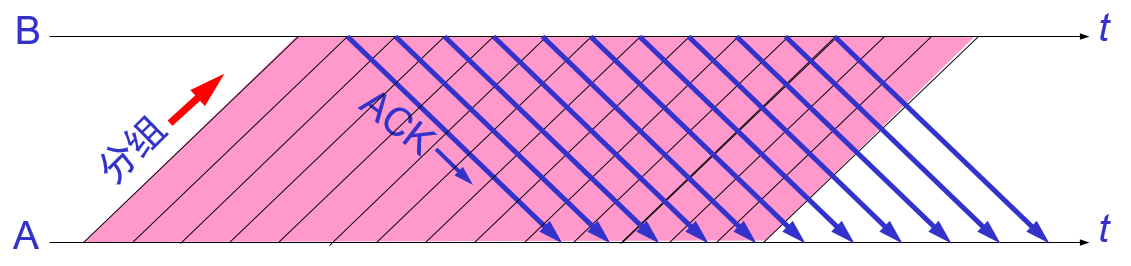
流水线传输就是发送方可以连续发送多个分组,不必每发完一个分组就停顿下来等待对方的确认。这样可使信道上一直有数据不断地在传送,从而提高信道的利用率。
流水线传输时,会使用到连续 ARQ 协议和滑动窗口协议。
连续 ARQ 协议
滑动窗口协议比较复杂,是TCP协议的精髓所在,在这里先给出ARQ协议最基本的概念,但不涉及到许多细节问题。
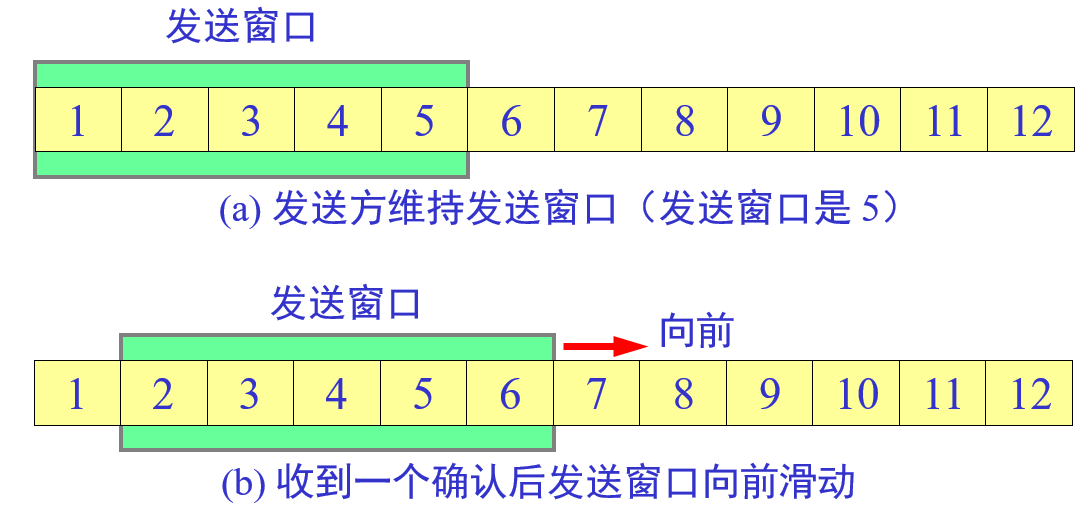
发送方维持的发送窗口,他的意义是:位于发送窗口内的 5 个分组都可以连续发送出去,而不需要等待对方确认。从而提高信道的利用率。当发送方每收到一个确认,就把发送窗口向前滑动一个分组的位置。
累积确认:接收方不必对收到的分组逐个发送确认,而是在收到几个分组后,对按序到达的最后一个分组发送确认,这就表示:到这个分组为止的所有分组都已正确收到了。累积确认有的优点是:容易实现,即使确认丢失也不必重传。缺点是:不能向发送方反映出接收方已经正确收到的所有分组的信息。
Go-back-N:当接收方检测出时序的信息后,要求发送方重发最后一个正确接受的信息帧之后的所有未被确认的帧;或者当发送方发送了n个帧后,若发现该n帧的前一帧在计时器超时区间内仍未返回其确认信息,则该帧被判定为出错或丢失,此时发送方不得不重新发送该出错帧及其后的n帧。
以字节为单位的滑动窗口
超时重传时间的选择
- 重传机制是 TCP 中最重要和最复杂的问题之一。
- TCP 每发送一个报文段,就对这个报文段设置一次计时器。只要计时器设置的重传时间到但还没有收到确认,就要重传这一报文段。
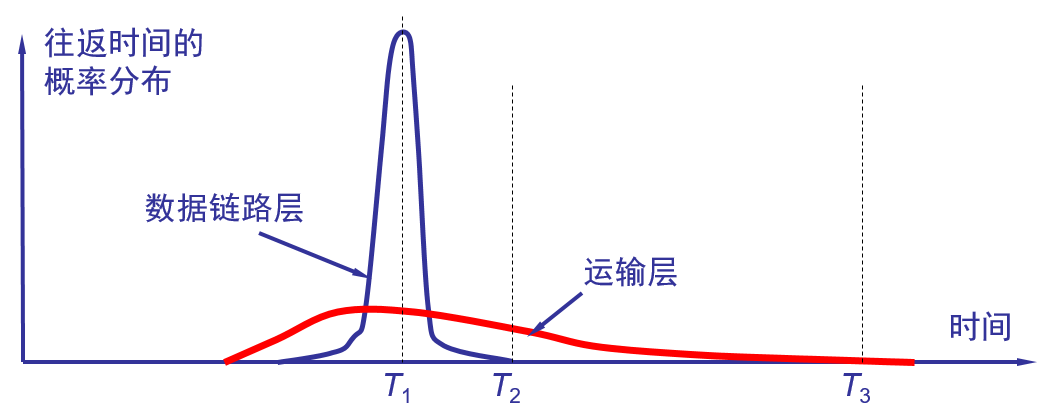
往返时延的方差很大
由于 TCP 的下层是一个互联网环境,IP 数据报所选择的路由变化很大。因而运输层的往返时间的方差也很大。
加权平均往返时间RTT
TCP才用了一种自适应算法,它记录一个报文段发出的时间,以及收到相应的确认的时间。这两个时间之差就是报文段的往返时间RTT。
TCP 保留了 RTT 的一个加权平均往返时间 RTTs(这又称为平滑(smooth)的往返时间,因为是加权平均,所以是平滑的)。
第一次测量到 RTT 样本时,RTTS 值就取为所测量到的 RTT 样本值。以后每测量到一个新的 RTT 样本,就按下式重新计算一次 RTTS:
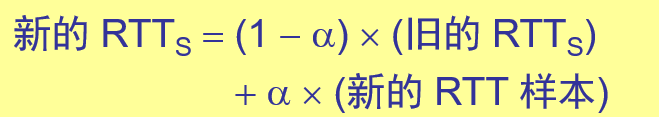
式中,0=<a<1。若 a 很接近于零,表示 RTT 值更新较慢(新的RTTs值和旧的RTTs值相比变化不大)。若选择 a 接近于 1,则表示 RTT 值更新较快(新的RTTs值受新的RTT样本的影响较大)。
RFC 2988 推荐的 a 值为 1/8,即 0.125。
超时重传时间RTO
显然,RTO 应略大于上面得出的加权平均往返时间 RTTs
RFC 2988 建议使用下式计算 RTO:
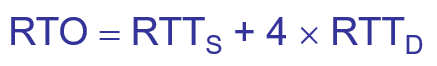
RTTD 是 RTT 的偏差的加权平均值,他与RTTs和新的RTT样本之差有关。
RFC 2988 建议这样计算 RTTD。第一次测量时,RTTD 值取为测量到的 RTT 样本值的一半。在以后的测量中,则使用下式计算加权平均的 RTTD:

β是个小于 1 的系数,其推荐值是 1/4,即 0.25。
然而往返时间的测量是相当复杂的:
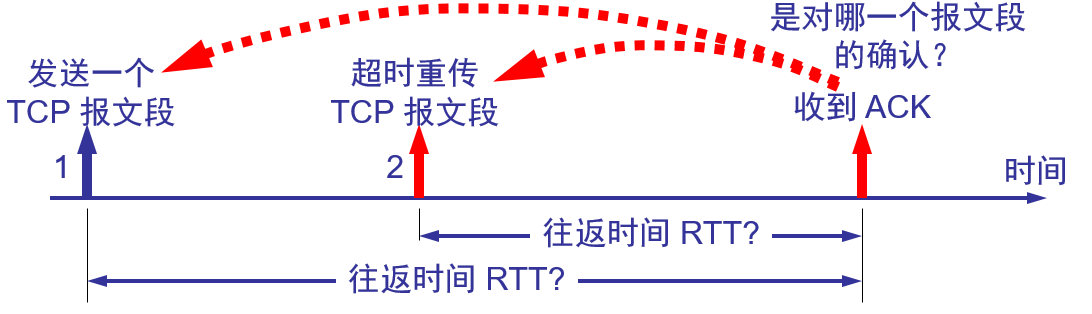
Karn 算法:
为了解决上面那个问题,Karn提出了一个算法.
在计算平均往返时间 RTT 时,只要**报文段重传了,就不采用其往返时间样本。这样得出的加权平均平均往返时间 RTTS 和超时重传时间 RTO 就较准确。 **
但是,这又有了新的问题、设想出现这样的情况:报文段的时延突然增大了很多。因此在原来得出的重传时间内,不会收到确认报文段。于是就重传报文段。但根据Karn算法,不考虑重传的报文段的往返时间样本。这样,超时重传时间就无法更新。
修正的 Karn 算法
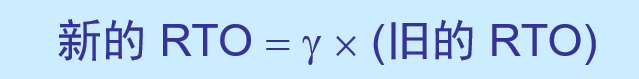
系数 γ 的典型值是 2 。
当不再发生报文段的重传时,才根据报文段的往返时延更新平均往返时延 RTT 和超时重传时间 RTO 的数值。
实践证明,这种策略较为合理。